本文共 2548 字,大约阅读时间需要 8 分钟。
今天学习了强连通分量的Kosaraju算法,网上写的人也不多,但是跟着视频教程讲解,还有去网上搜了博客,感觉他们的讲解都存在一定的问题,我在学习的时候碰到的一些困惑,他们并没有讲的清楚明白,当然,他们说的大致的思路是正确的。
算法思想:
先说说什么是强连通分量 强连通分量是针对有向图定义的,为了区别无向图的联通分量的概念。在一个强连通分量中,任意两点都相互可达。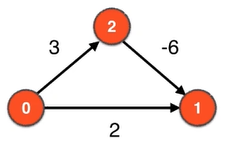 这个图中就存在三个强连通分量,分别{0}、{1}、{2},因为这三个点相互不可达,但是自己到自己还是可到达的。
这个图中就存在三个强连通分量,分别{0}、{1}、{2},因为这三个点相互不可达,但是自己到自己还是可到达的。
上图就是一个联通分量,应为在这个图中,两两都可达。
观察上面那个强连通分量图,在有向图中就是个环,很明显可以看到,从0->2有条边,但是2不能直接回到0,若2要能回到0必须得找到另外一条路径,就构成了环(自己理解,并无实际证明)
如何求强连通分量的个数呢?
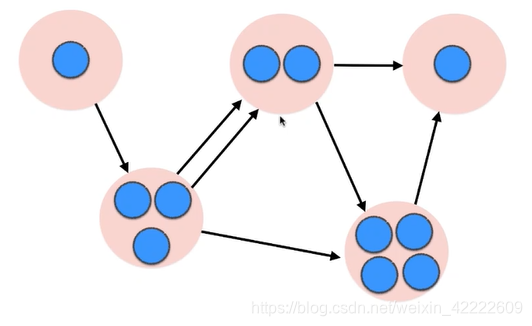
将所有联通分量看成一个点,得到的图一定是有向无环图,若得到的图存在环
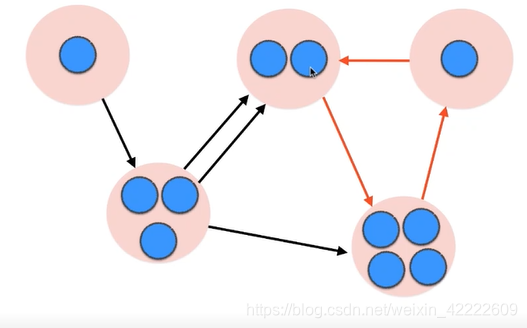
红色的边组成的环构成了一个联通分量。
根据这个图,可以看出,如果从出度为0的点进行深度优先遍历,那么一定会在这个顶点所在的联通分量遍历完以后退出。在遍历该联通分量时,不会去遍历其他的联通分量,因为其出度为0。
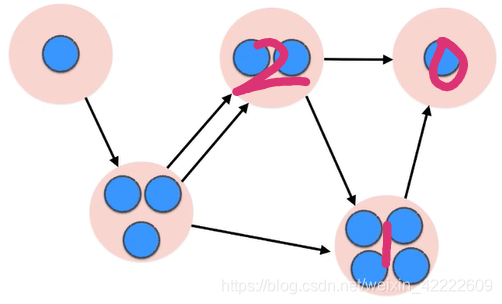
遍历完0号联通分量后,再遍历1号联通分量,因为1号联通分量出度为1,但是它是指向0号联通分量的,0号刚刚被遍历完,所以遍历完1号联通分量不会跑到其他联通分量中去。
按照这个思路,按顺序进行深度优先遍历,我们可以计算出强连通分量的个数。所以重点是找到这个顺序。 如果对拓扑排序了解的话,若把上图进行拓扑排序的话,这个序列中0号联通分量必然排在最后一个,拓扑排序的思想和这这个算法的的顺序思想类似。求解这个拓扑排序要使用 深度优先遍历的后序 遍历算法。这次搜索是对原图进行的。 我们需要了解两个时间戳的概念——最早发现时间和最晚完成时间,我们可以参照算法导论给出几个符号表示: 对于U集合,有: d_min{U}:最早发现时间;d_max{U}:最晚发现时间; f_min{U}:最早完成时间;f_max{U}:最早完成时间 。 发现时间,指的是搜索开始的时间;完成时间,指的是搜索结束的时间。对于U集合,发现时间和完成时间的最值有四个(上面四个),指的是所有的点都符合的一个最值。 算法导论里有个引理:22.14:设C和D为有向图G={ V , E }的两个不同的强连通分量。假如存在一条边( u , v )∈E,这里u∈C,v∈D,则f_max{C} > f_max{D} 。 它说明了一个非常重要的事:用任意的访问顺序搜索一个弱连通图,图里的强连通分量的最晚完成时间顺序一定。 我觉得这点才是这个算法思路的核心,困惑了我好久,因为无论你用正图或者反图进行深度优先遍历,得到一个序列必然有可能几个联通分量混在一起,而不是独立的界限的。但是这个引力说明了,每个强连通分量的最晚完成时间的顺序是一定的。现在我们不能把一个联通分量看成一个点了,我们把所有点都拆开看,顺便用例子验证这个引理的合理性。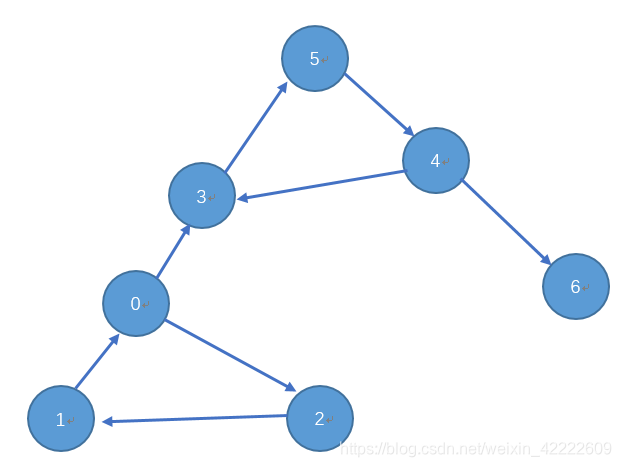
上图中有3个强连通分量A{0,1,2}、B{3,4,5}、C{6}
以1为顶点进行深度优先的后序遍历: 6、4、5、3、0、2、1; 每个联通分量最晚完成时间的顺序是:C B A 以4为顶点得到的序列为: 3、5、6、4、1、2、0; 每个联通分量最晚完成时间的顺序是:C B A 对应上了引理得出的结论;我们再来看看拓扑伪排序:6、4、5、3、0、2、1;和3、5、6、4、1、2、0;这两个拓扑排序的中前面C号联通分量和B号联通分量中的顶点是混在一起的,而A号联通分量的中的顶点一定排在这个序列的最后,思考下这句话,有两点,一个是A号联通分量为何排在最后,另一个是A中有顶点必然排在这个伪拓扑排序的最后。 先思考第一点:因为现在说的是A号联通分量,把他看成一个缩点,(在这里看成缩点的原因是,有向有环图不存在拓扑排序;看成缩点图更好理解)那么他在真正的拓扑排序应该排在第一位,第一位的特点是入度为0。 再看看第二点:因为 图里的强连通分量的最晚完成时间顺序一定。若这个强连通分量的排在最晚完成时间顺序的最后,那么在伪拓扑排序的最后的顶点一定是属于该强连通分量。所以,我们取出该伪拓扑排序的最后一点,他一定是属于满足第一点要思考的。因为A号联通分量的入度为零,那么将图中所有边全部反向,那么强连通分量的性质没有发生变化,变化的是每个联通分量的入度和出度发生了转化。A点的出度变为0,而A中的顶点必在伪拓扑排序的最后一点。将那个伪拓扑排序进行反序,得到的拓扑排序中靠前的一定是强连通分量中的最晚完成时间。按照开头求解联通分量的思想,强连通分量即可求。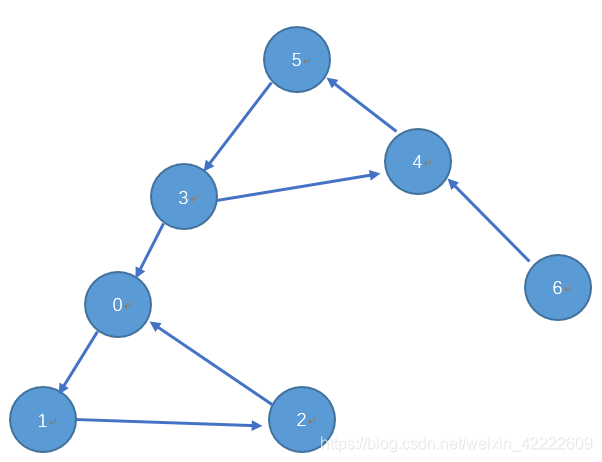
刚刚一直都在强调的是A号联通分量,再把 每个联通分量最晚完成时间的顺序依次带入开头介绍的强连通分量的求法即可求解。
SCC的Kosaraju算法模板
//-----Kosaraju
vector<int>G[maxn],G2[maxn];
vector<int>S;
int vis[maxn],sccno[maxn],scc_cnt;
void dfs1(int u)
{
if (vis[u]) return;
vis[u]=1;
for (int i=0;i<G[u].size();i++) dfs1(G[u][i]);
S.push_back(u);
}
void dfs2(int u)
{
if (sccno[u]) return;
sccno[u]=scc_cnt;
for (int i=0;i<G2[u].size();i++) dfs2(G2[u][i]);
}
void find_scc(int n)
{
scc_cnt=0;
S.clear();
memset(sccno,0,sizeof(sccno));
memset(vis,0,sizeof(vis));
for (int i=0;i<n;i++) dfs1(i);
for (int i=n-1;i>=0;i--)
{
if (!sccno[S[i]])
{
scc_cnt++;
dfs2(S[i]);
}
}
}
//-----------
转载地址:http://wwuii.baihongyu.com/